Abstract
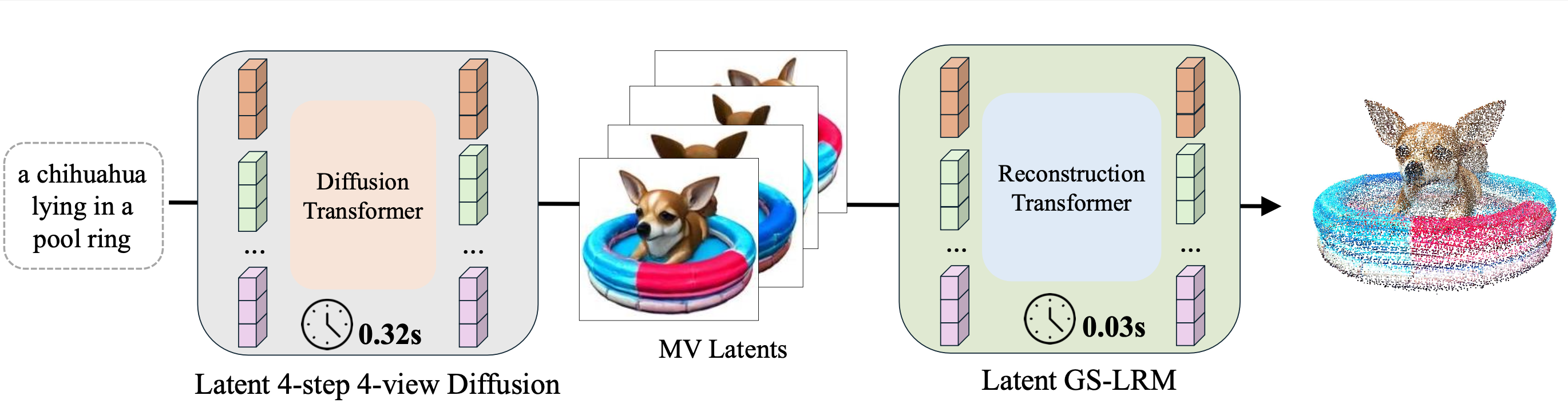
We present Turbo3D, an ultra-fast text-to-3D system capable of generating high-quality Gaussian splatting assets in under one second. Turbo3D employs a rapid 4-step, 4-view diffusion generator and an efficient feed-forward Gaussian reconstructor, both operating in latent space. The 4-step, 4-view generator is a student model distilled through a novel Dual-Teacher approach, which encourages the student to learn view consistency from a multi-view teacher and photo-realism from a single-view teacher. By shifting the Gaussian reconstructor's inputs from pixel space to latent space, we eliminate the extra image decoding time and halve the transformer sequence length for maximum efficiency. Our method demonstrates superior 3D generation results compared to previous baselines, while operating in a fraction of their runtime.
Comparisons to Other Methods
We compare our method with LGM, Instant3D, SV3D and TripoSR, and visualize the renderings of the generated 3D assets. Since SV3D only outputs videos instead of 3D assets, we directly show the videos with only 21 frames generated by SV3D. Moreover, the inputs of SV3D and TripoSR are the same images, since they are image-to-3D methods.
More Results
We randomly select 72 text prompts from about 450 text prompts and show the results of our Turbo3D.
BibTeX
@article{huturbo3d,
title={Turbo3D: Ultra-fast Text-to-3D Generation},
author={Hanzhe Hu and Tianwei Yin and Fujun Luan and Yiwei Hu and Hao Tan and Zexiang Xu and Sai Bi and Shubham Tulsiani and Kai Zhang},
journal={arXiv preprint arXiv:2412.04470},
year={2024}
}